Machine Learning(Hung-yi Lee)
2020年李宏毅机器学习课程。连接
此Blog记录较省略,只适用于作者。
学习路线: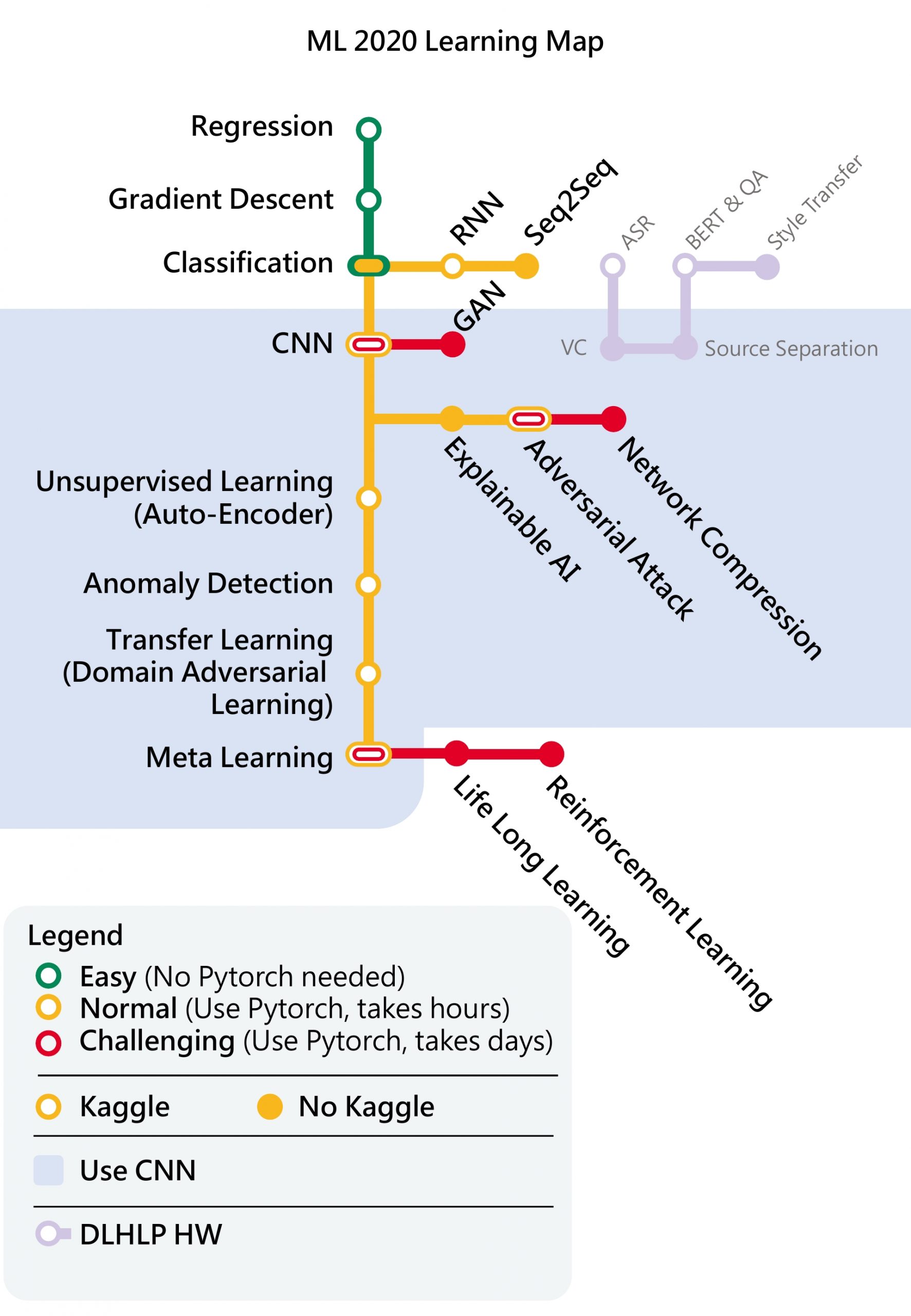
Regression
例:宝可梦的pc值
Model: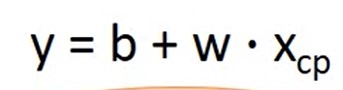
损失函数: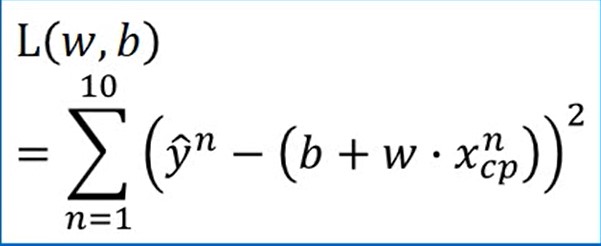
求: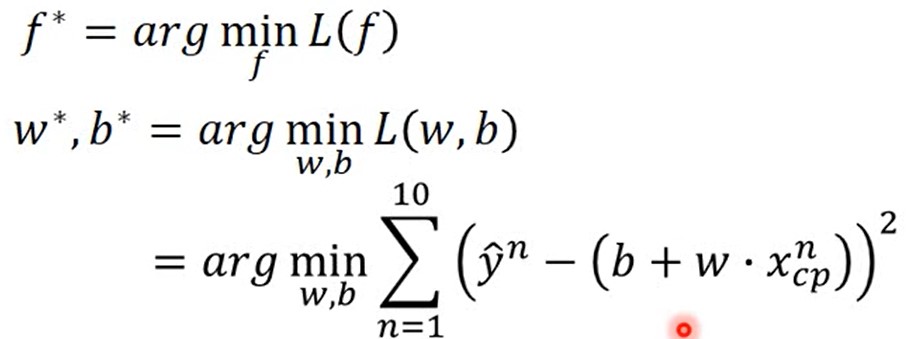
对w,b求偏微分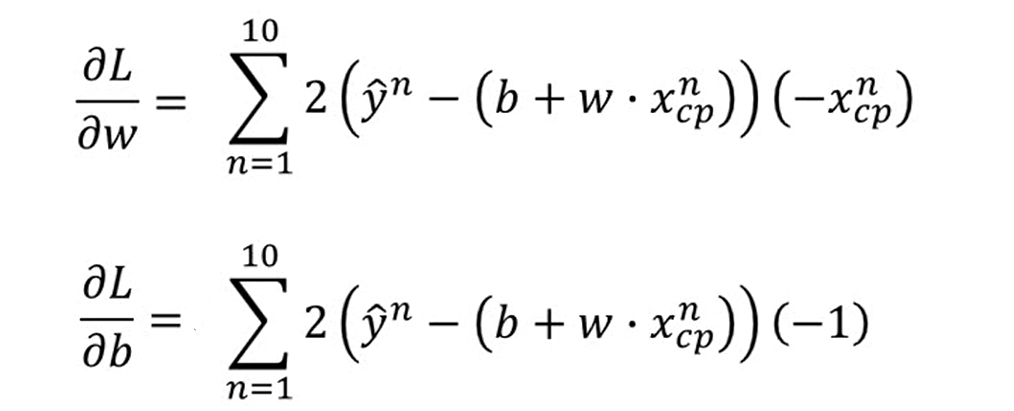
求得:b=-188.4w=2.7
则:y=-188.4+2.7X(n)
Training Data:average Error:31.9
Testing Data:average Error:35.0
选择其他Model如:
求得:b=-10.3w1=1.0w2=2.7×10^-3
则:y=-188.4+2.7X(n)
Training Data:average Error:15.4
Testing Data:average Error:18.4
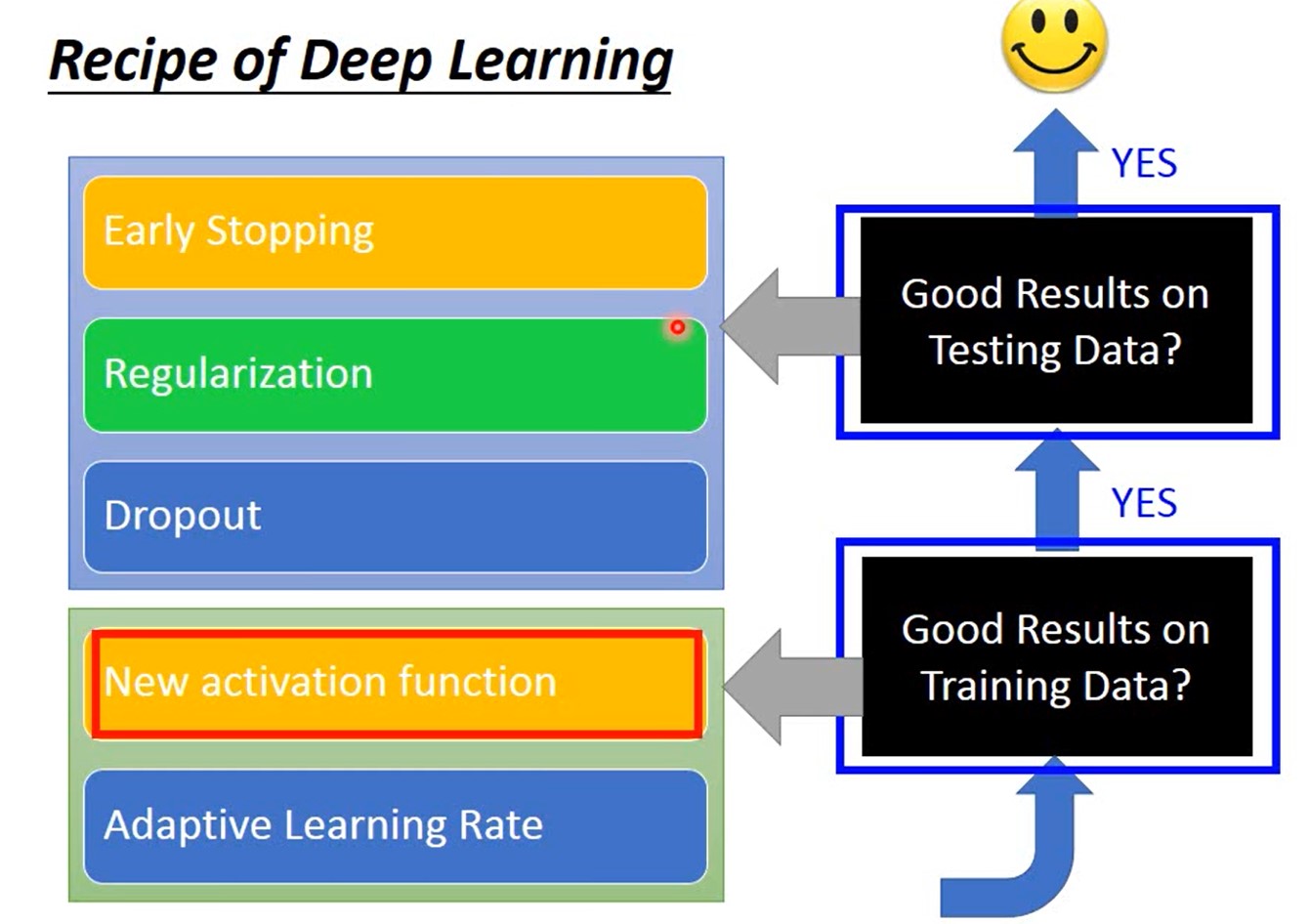
More Model: 在训练集上Model越复杂,error越低。测试集上越高,导致 Overfitting
重新设计Model(宝可梦):
model与种类有关,设计不同种类得model
model: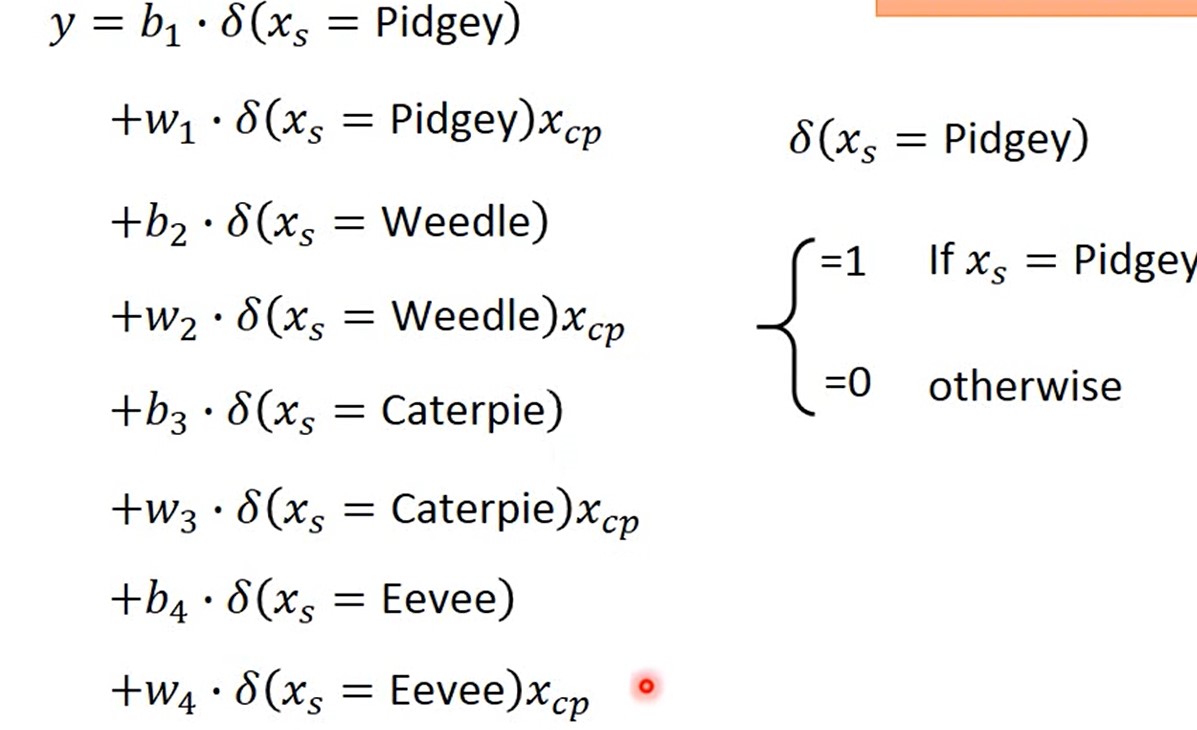
result: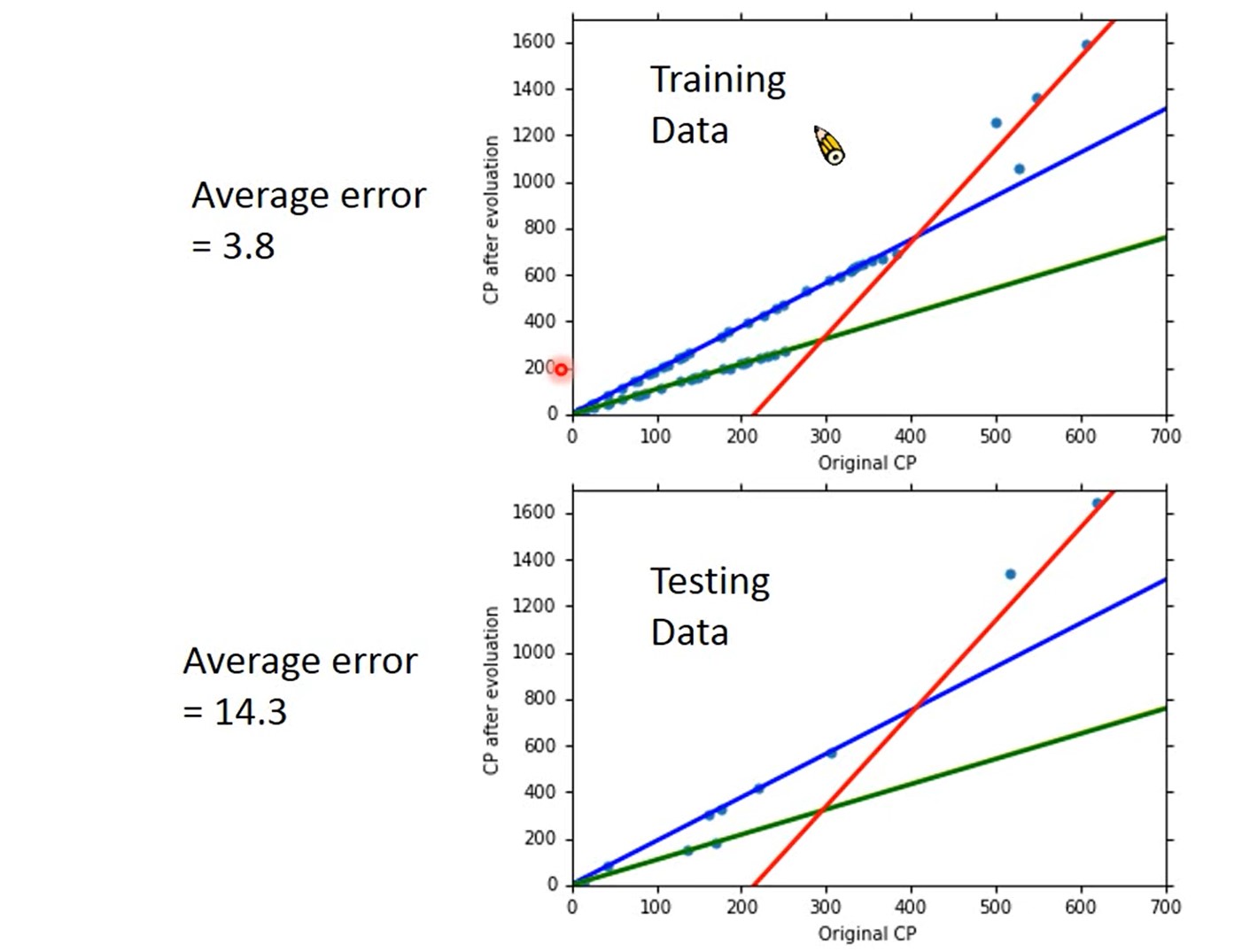
那PC值可能与其他因素有关(如,高度):
Redesign Model: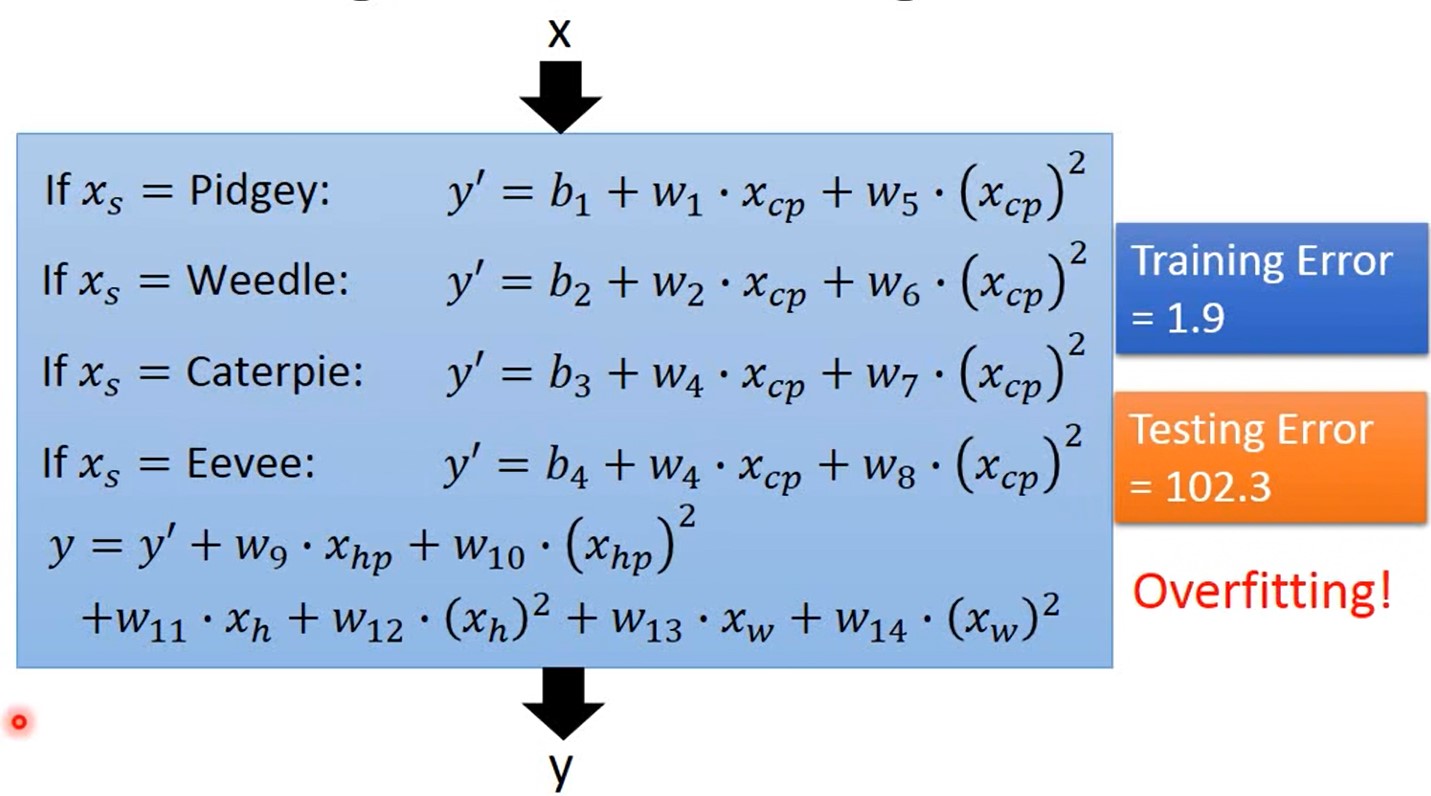
Regularization:
平滑程度与b无关,无需考虑b
Result: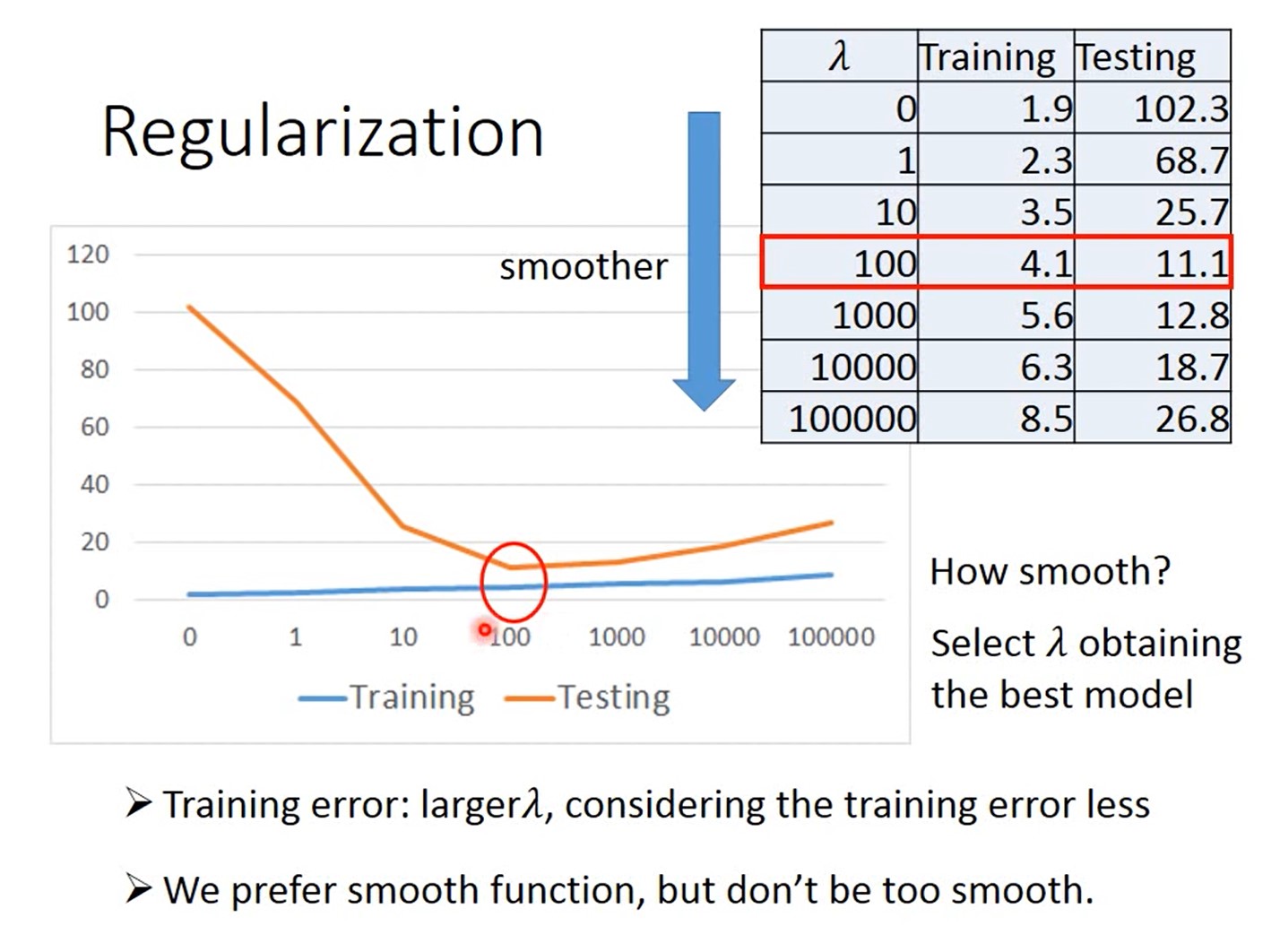
结论,λ=100时候,最合适
Basic Concept
Bias and Variance(偏差与方差)
- Bias大: Underfintting(
Model cannot fit the training examples) - Variance 大:Overfitting(
Can fit training data, but large error on testing data)
Bias 大:
- Redesign model:
- 增加特征
- 更复杂的Model
Variance 大:
- More data
- Regularization(有可能伤害Bais)
Gradient Descent
梯度下降如图: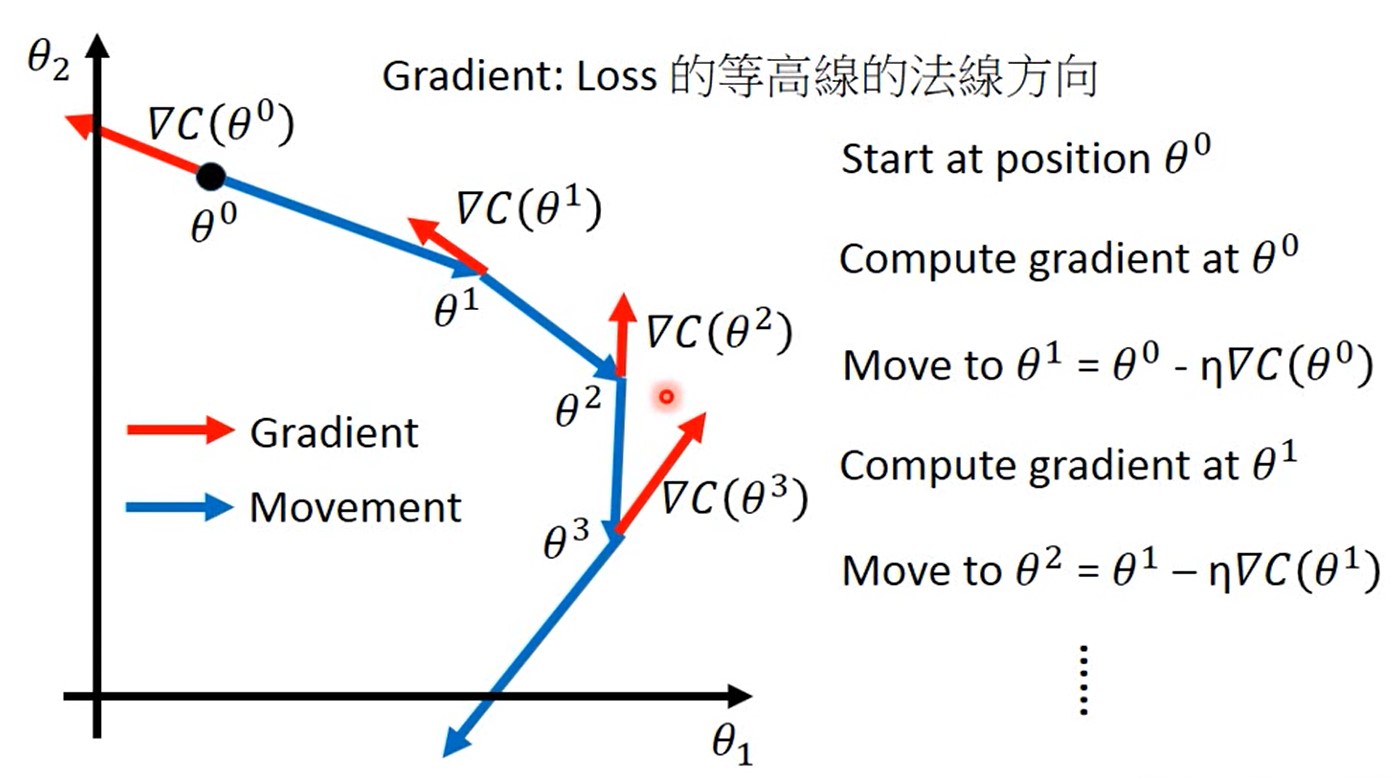
tip1:
Learning rates
1.画出Loss变化图,便于观察
2.Adaptive Learning rate2.1. 开始使用较大的Learning rate,随着靠近目标,不断减小Learning rate。如Adagrad
Adagrad: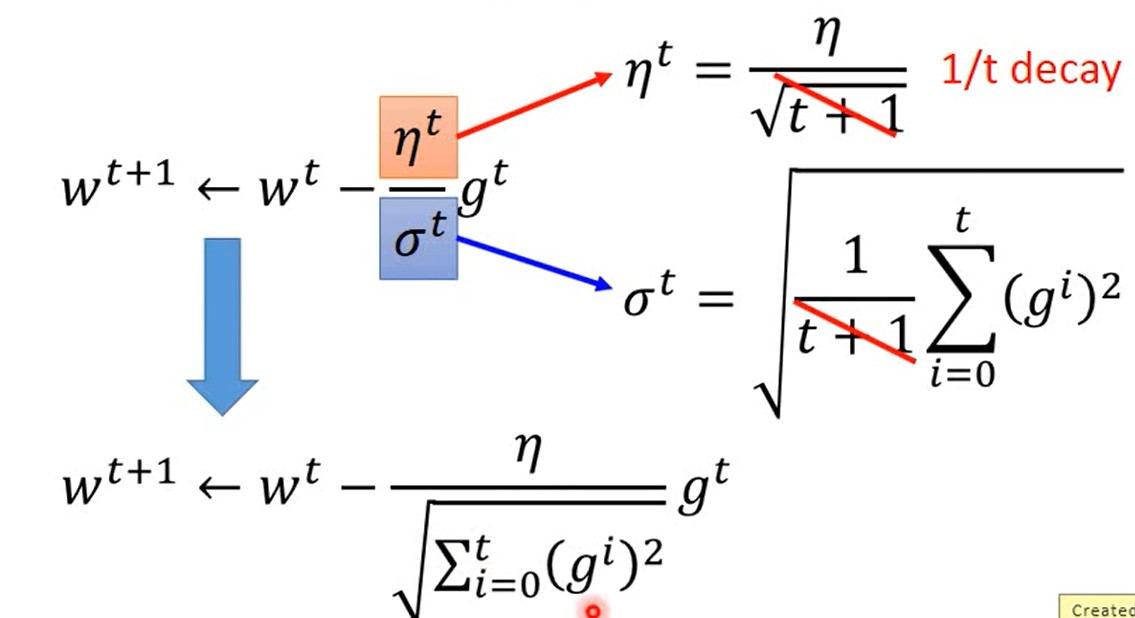
其中: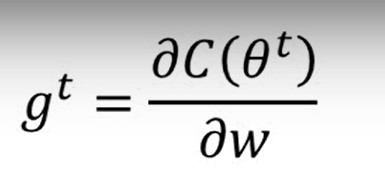
tip2:随机梯度下降
Stochastic Gradient Descent(SGD)
随机取其中一个example做Loss的Gradient
优点:速度快
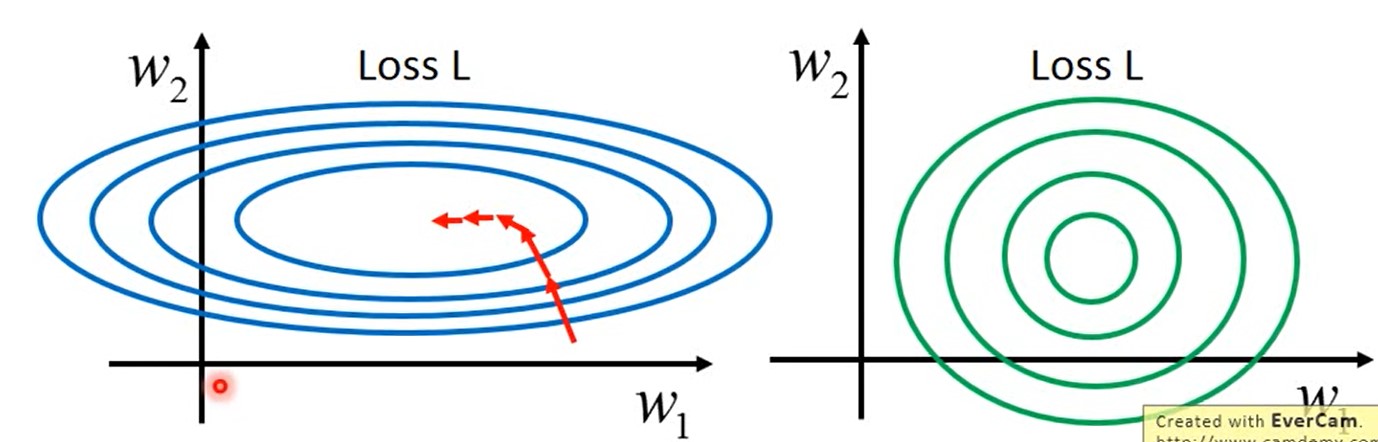
tip3:特征缩放
Feature Scaling(特征缩放,归一化)
不同的feature有共同的scaling
Taylor Series
梯度下降的限制
梯度下降极慢时梯度≈0,停在水平点梯度=0,停在局部最小非极小值
优化器
梯度下降有三类优化方法。
- 批量梯度下降(batch、off-line)
- 随机梯度下降(Stochastic Gradient Descent)
- 小批量随机梯度下降(mini-batch stochastic)
定义:
w:待优化参数
f(w):目标函数
α:初始学习率
迭代优化,在每个epoch t
- 计算目标函数关于当前参数的梯度:
- 根据历史梯度计算一阶动量和二阶动量:
- 计算当前时刻的下降梯度:
- 根据下降梯度进行更新:
GD
在有限视距内寻找最快路径下山“,因此每走一步,参考当前位置最陡的方向(即梯度)进而迈出下一步。- 缺点:
- 训练速度慢:每走一步都要要计算调整下一步的方向,下山的速度变慢。在应用于大型数据集中,每输入一个样本都要更新一次参数,且每次迭代都要遍历所有的样本。会使得训练过程及其缓慢,需要花费很长时间才能得到收敛解。
- 容易陷入局部最优解:由于是在有限视距内寻找下山的反向。当陷入平坦的洼地,会误以为到达了山地的最低点,从而不会继续往下走。所谓的局部最优解就是鞍点。落入鞍点,梯度为0,使得模型参数不在继续更新。
- 缺点:
BGD
在下山之前掌握了附近的地势情况,选择总体平均梯度最小的方向下山。
每次权值调整发生在批量样本输入之后,而不是每输入一个样本就更新一次模型参数。这样就会大大加快训练速度。SGD
随机梯度下降像是一个盲人下山,不用每走一步计算一次梯度,但是他总能下到山底,只不过过程会显得扭扭曲曲。优点:
- 虽然SGD需要走很多步的样子,但是对梯度的要求很低(计算梯度快)。而对于引入噪声,大量的理论和实践工作证明,只要噪声不是特别大,SGD都能很好地收敛。
- 应用大型数据集时,训练速度很快。比如每次从百万数据样本中,取几百个数据点,算一个SGD梯度,更新一下模型参数。相比于标准梯度下降法的遍历全部样本,每输入一个样本更新一次参数,要快得多。
缺点:
- 下降速度慢,而且可能会在沟壑的两边持续震荡,停留在一个局部最优点。
SGDM
SGD with Momentum
为了抑制SGD的震荡,SGDM认为梯度下降过程可以加入惯性。下坡的时候,如果发现是陡坡,那就利用惯性跑的快一些。
在SGD基础上引入了一阶动量:一阶动量是各个时刻梯度方向的指数移动平均值,约等于最近
个时刻的梯度向量和的平均值。也就是说,t时刻的下降方向,不仅由当前点的梯度方向决定,而且由此前累积的下降方向决定。
的经验值为0.9,这就意味着下降方向主要是此前累积的下降方向,并略微偏向当前时刻的下降方向。想象高速公路上汽车转弯,在高速向前的同时略微偏向,急转弯可是要出事的。
NAG
Nesterov Accelerated Gradient
在Momentun中小球会盲目地跟从下坡的梯度,容易发生错误。所以需要一个更聪明的小球,能提前知道它要去哪里,还要知道走到坡底的时候速度慢下来而不是又冲上另一个坡。
SGD 还有一个问题是困在局部最优的沟壑里面震荡。想象一下你走到一个盆地,四周都是略高的小山,你觉得没有下坡的方向,那就只能待在这里了。可是如果你爬上高地,就会发现外面的世界还很广阔。因此,我们不能停留在当前位置去观察未来的方向,而要向前一步、多看一步、看远一些。NGA是在SGD、SGD-M的基础上的进一步改进,改进点在于步骤1。我们知道在时刻t的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步,那个时候再怎么走。因此,NAG在步骤1,不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步,那个时候的下降方向:
然后用下一个点的梯度方向,与历史累积动量相结合,计算步骤2中当前时刻的累积动量。AdaGrad
AdaGrad算法,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根。具有代价函数最大梯度的参数相应地有个快速下降的学习率,而具有小梯度的参数在学习率上有相对较小的下降。
对出现比较多的类别数据,Adagrad给予越来越小的学习率,而对于比较少的类别数据,会给予较大的学习率。因此Adagrad适用于数据稀疏或者分布不平衡的数据集。- 优点
- 不需要人为的调节学习率,它可以自动调节
- 缺点
- 随着迭代次数增多,学习率会越来越小,最终会趋近于0。
- 优点
AdaDelta / RMSPeop
RMSProp算法修改了AdaGrad的梯度积累为指数加权的移动平均,使得其在非凸设定下效果更好。
AdaGrad算法和RMSProp算法都需要指定全局学习率,AdaDelta算法结合两种算法每次参数的更新步长。优缺点
在模型训练的初期和中期,AdaDelta表现很好,加速效果不错,训练速度快。
在模型训练的后期,模型会反复地在局部最小值附近抖动。Adam
Adam和Nadam的出现就很自然而然了——它们是前述方法的集大成者。我们看到,SGD-M在SGD基础上增加了一阶动量,AdaGrad和AdaDelta在SGD基础上增加了二阶动量。把一阶动量和二阶动量都用起来,就是Adam了——Adaptive + Momentum。Nadam
Nesterov + Adam = Nadam
深入参考:
Classification
DeepLearning
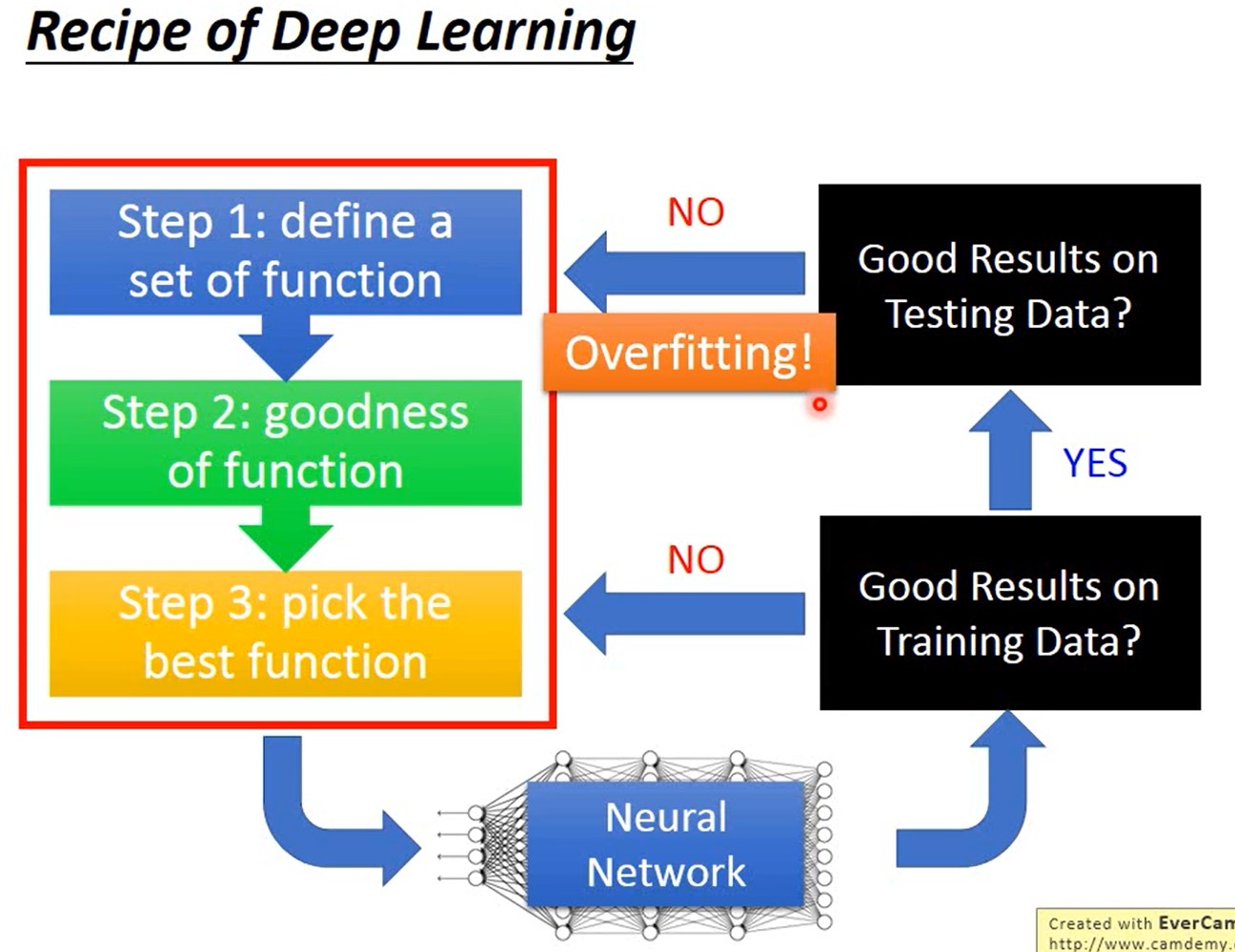
深度学习步骤
step 1:Neural Network
step 2:goodness of function
step 3:pick the best function